Database performance is a crucial factor in web application performance, and can mean the difference between a responsive web application and a slow one. Here, we summarise methods for identifying database performance issues, and how to approach fixing them.
Benchmarking Overall Performance
First, it is worth establishing whether database queries are a performance bottleneck, or whether you should be focusing your efforts on something else. There are a number of ways to do this, and two that I’ve found simple and effective are django-snippetscream and django-debug-toolbar.
Install django-snippetscream:
1
| |
and add the following middleware class to settings.py:
1
| |
Now, you can simply append ?prof to your application URLs to profile the code run to generate the page. This gives a quick way of telling whether any particular methods are consuming disproportionate resources. Sample output is shown below.
1 2 3 4 5 6 7 | |
See the snippetscream documentation for more details.
The django-debug-toolbar is another easy-to-use profiler (and has many other functions). To install:
1
| |
And add the following to your settings.py:
1 2 3 | |
Now, when you visit your site in a browser, the SQL query view will display queries that have been executed and the time taken.
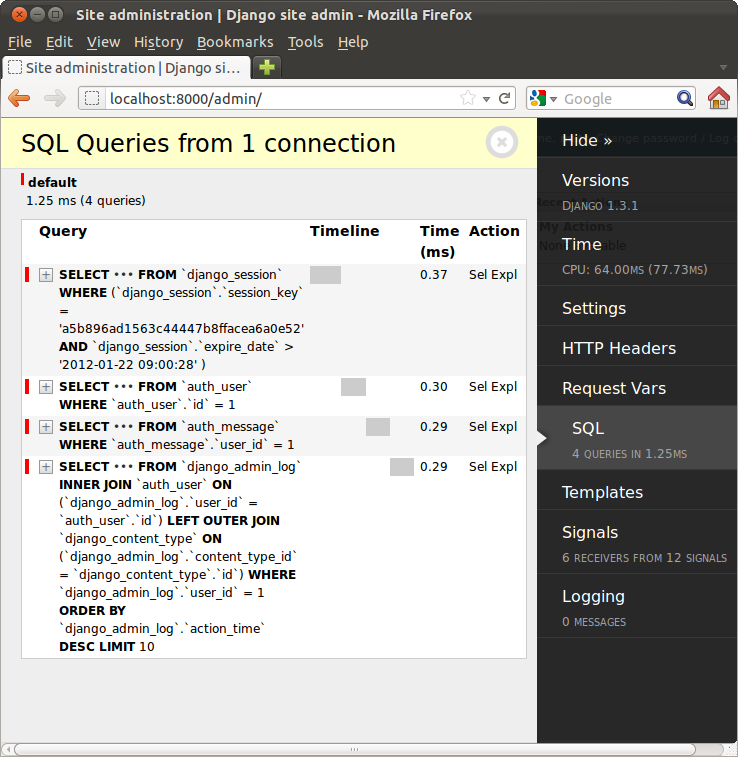
So, you can now judge for yourself whether your application is slow executing queries or if there is some other performance bottleneck. To deal with database issues, read on.
A closer look at SQL query generation in Django
Now that you have a couple of tools by which to measure performance, let’s look at some examples of optimising database performance. We’ll use the following simple models for our discussion.
1 2 3 4 5 6 7 8 | |
Fetching Multiple Models at Once
For our first example, assume we want to print a list of articles with the author’s name. We could do the following:
1 2 3 | |
How many SQL queries would this generate? Let’s use debugsqlshell:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 | |
For each article, there will be a separate query to retrieve details about the user. We can avoid this by using select_related, which tells
Django’s ORM to select related models in the same query:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 | |
Here, we see that the article’s owner is retrieved using the JOIN clause. So in this example, use of select_related has halved the number of queries executed.
One thing that should be remembered about select_related is that it does not work for many-to-many fields.
In our example, that means that article tags would not be fetched in a single query.
For these model attributes, there is a new method included in Django 1.4 called prefetch_related. Django 1.4 is currently an alpha release, download it here.
Let’s look at how prefetch_related reduces the number of queries with our example classes. First, observe what happens if we access article tags without prefetching:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 | |
Separate queries are generated to retrieve the tags. And now with tag prefetching:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 | |
As we can see, all tags are fetched in a singlee query using an IN statement. So, select_related and prefetch_related are two effective ways of reducing the number of queries needed for accessing models.
Other techniques for reducing generated queries
If you find that your models are too complex to benefit from the above methods, you can always start writing your own SQL. Of course, this comes with the usual disclaimers: your code may be less portable between databases, and may be harder to maintain.
One method of doing this is to use the extra() method on a queryset like so:
1
| |
This can be useful if you need, for example, a nested SELECT clause. The other option is to use raw queries, which are documented here.
One last point worth mentioning is to be careful with the use of iterator(), which loads only a subset of a query set into memory. If you then iterate over this queryset, this can generate lots of queries. Here’s a longer discussion.
Conclusion
Hopefully this post has provided a useful discussion of query generation in Django and how you can optimise database access in your application.
I’ll close with a couple of useful resources: some useful tips on writing performant models, and the official django optimization page.