Coder Weekly has been running for over a year. Over that time, the subscriber base has continued to grow (now approaching 5,000), and the format and content has changed somewhat.
I thought that this would be a good point to look back at what’s worked, and describe some changes that will be made to Coder Weekly in the near future.
Link submissions
I’ve had many tips submitted for content over the past year. If I recall correctly, all of them have been used because they’ve all been of high quality. I encourage people to keep submitting tips as there’s always something I will miss!
One thing to bear in mind when submitting tips is that a high proportion of readers are on mobile devices.
Our Google Analytics Automated Reports collect data about Traffic Sources, visitors Age and Gender from third-party Cookies, Android Advertising ID
Job postings
This week I’ll be accepting the first job postings to Coder Weekly. This is a trial to see how things work – in particular, I want make sure it provides value both to subscribers, and those submitting job postings. Suffice it to say that there will be no agency or recruiter postings.
Coder Weekly has been running for over 6 weeks now, so it seems like a good time to share some numbers. So far, the community feedback has been really positive and we’ve reached 3,000 email subscribers, with another 800 or so on RSS.
Initial Traffic
The first peak in this graph is the submission to Hacker News, and the second is the submission to /r/programming. You can see that, overall, reddit sent a lot more visitors. Due to the ranking algorithm differences of the two sites, traffic from reddit also continued for longer.
Below, you can see how these spikes in traffic translated into new subscribers (y-axis shows new subs/day). You can’t quite attribute all signups to Hacker News and reddit since there were other traffic sources too (e.g. twitter), but it gives a reasonable indication of the conversions.
Overall, well over 2,000 subscriptions occurred from these ~19,000 unique visitors, a conversion rate over 10%. Unfortunately I haven’t run the numbers from the new version of the landing page, so I can’t on speculate whether this has improved the conversion rate.
Finally, the image below shows the number of RSS subscribers, which quickly rose past 800. It was clear from the outset that a large number of readers preferred this, so I’m glad Mailchimp made it so easy to offer.
Ongoing Growth
After each issue, there is an uptick in subscribe rate. It’s great that people are tweeting about Coder Weekly and forwarding the emails. Conversely, unsubscribe rates are extremely low – we’re looking at between 2-5 subscribers per issue.
So, although we haven’t enjoyed the same incredible growth of the first week, there is steady growth that seems to be driven primarily by current subscribers.
Click Data
There’s lots to be said about click rates for different articles. As you’d expect, there is a strong correlation between the position in the list and click rate. The article’s title is clearly an important factor too, with titles that describe an opinion or technique doing well. Below, you can see the top clicked links in Coder Weekly Issue #5.
I intend to do a longer post discussing click data in future, hopefully with some interesting split testing data.
The Future
I hope this brief overview has provided some interesting numbers for those of you who are curious. In future, there are a few ideas I’d like to work on. Providing a separate feed for individual stories is something that’s been asked for many times that I’m still working on, and it would also be illuminating to do some split testing on the landing page.
Source code modification can be useful in a number of testing and analysis scenarios. Here, we’ll look at how you can modify Python source code using the ast module, and some tools where this technique is used.
The CPython compilation process
To begin, let’s take a look at the CPython compilation process, as described in PEP 339.
Detailed knowledge of these steps isn’t required for reading this article, but it helps to have a rough idea of the whole process.
First, a parse tree is generated from the source code. Next, an Abstract Syntax Tree (AST) is built from the parse tree. From the AST, a control flow graph is generated, and finally, the code object is compiled from the control flow graph.
Marked in blue is the AST stage, since that’s what we’ll be focusing on today. The ast module appeared in its current form in Python 2.6, and exposes a simple method of visiting and modifying the AST.
From there, we can generate a code object from our modified AST. We can also re-generate source code from our modified AST for explanatory purposes.
Creating an AST
Let’s define a simple expression, an add function, and inspect the generated AST.
As we can see, Module is the parent node. The Module body contains a list with a single element: our function definition. The function definition has a name, list of arguments, and a body. The body contains a single Return node, which contains the Add operation.
Modifying the AST
How can we modify this tree and change how the code works? To illustrate, let’s do something crazy that you would never want to do in your code. We’ll traverse the tree, and replace the Add operation with a Mult operation. See, I told you it was crazy!
We’ll start by subclassing the NodeTransformer class, and defining the visit_BinOp method which is called when the transformer visits a binary operator node:
Now that we’ve defined our transformer which performs this unhealthy action, let’s see it run on the expression defined above:
123
>>> parser.visit(expr_ast)
{'op': <_ast.Add object at 0x226b810>, 'right': <_ast.Name object at 0x285fe10>, 'lineno': 1, 'col_offset': 28, 'left': <_ast.Name object at 0x285fdd0>}
{'op': <_ast.Mult object at 0x28eb090>, 'right': <_ast.Name object at 0x285fe10>, 'lineno': 1, 'col_offset': 28, 'left': <_ast.Name object at 0x285fdd0>}
You can see the Add node is replaced with a Mult, as shown by the modified __dict__. There are a couple of things we haven’t dealt with here, like visiting child nodes, but this is enough to illustrate the principle.
Compiling and executing the modified AST
After adding a call to our operation, i.e.:
1
print add(4, 5)
…to the end of our script, let’s see how the code evaluates:
As we can see, the * operator has replaced +. Unparse is useful for understanding how your AST transformer modifies code.
Practical applications
Clearly, our above example serves little practical purpose. However, static analysis and modification of source code can be extremely useful.
You could, for instance, inject code for testing purposes. See this Pycon talk for an understanding of how a node transformer can be used to inject instrumentation code for testing purposes.
In addition, the pythoscope project uses an AST visitor to process source files and generate tests from method signatures.
Projects such as pylint also use an AST walking method to analyze source code.
In the case of pylint, Logilab have created a module which aims:
to provide a common base representation of python source code for projects such as pychecker, pyreverse, pylint…
Update: this post was written in early 2012 when Play 2.0 was beta software and is preserved for posterity. I make no promises about its suitability for current development with Play, and hope to do an updated post in future.
The source code for this guide can be found in the github repository.
Websockets allow full-duplex communication over a TCP socket, normally between a browser and a server-side application. In a similar vein to this post on websockets in Play 1.x, this article shows how to create a websockets-enabled application in Play 2.0.
Remember that Play 2.0 is still in beta, so the APIs shown below are subject to change. If that happens, I’ll endeavour to update this article with the changes.
Obtaining Play 2.0
I encountered an issue with the packaged beta, so I downloaded the Play source (full instructions):
123
git clone --depth=1 https://github.com/playframework/Play20.git
cd Play20/framework
./build
While it builds, you’ll probably want to get some coffee. Then, at the sbt prompt:
1
publish-local
Now, create the project:
1
./play new websocks2
You can run the eclipsify command (or equivalent) if you want to open the project in your IDE.
Creating the Websockets Controller
With setup done, let’s define the controller that will serve our index page and establish a websocket with the client. Open controllers/Application.java and add the following code:
package controllers;
import play.*;
import play.mvc.*;
import play.libs.F.Callback;
import views.html.*;
public class Application extends Controller {
public static Result index() {
return ok(index.render());
}
public static WebSocket<String> sockHandler() {
return new WebSocket<String>() {
// called when the websocket is established
public void onReady(WebSocket.In<String> in, WebSocket.Out<String> out) {
// register a callback for processing instream events
in.onMessage(new Callback<String>() {
public void invoke(String event) {
Logger.info(event);
}
});
// write out a greeting
out.write("I'm contacting you regarding your recent websocket.");
}
};
}
}
As you can see, alongside the pre-generated code, we’ve added a static method sockHandler that returns a websocket. The inner onReady method takes two arguments: the in channel and out channel.
At this point, we could pass those channels to a model which retains them. But for this example, we simply register a logger for inbound messages, and write a greeting message to the out socket.
Routing the Websocket Connection
Next, we need to add a route to our websocket connection. In conf/routes, add the following:
12345678910
# Routes
# This file defines all application routes (Higher priority routes first)
# ~~~~
# Home page
GET / controllers.Application.index()
GET /greeter controllers.Application.sockHandler()
# Map static resources from the /public folder to the /assets URL path
GET /assets/*file controllers.Assets.at(path="/public", file)
We don’t actually request /greeter explicitly; instead, we’ll use a reverse generated URL in our template.
Adding the Template
Now that we have our controller and route in place, we can specify the client-side code for our websocket.
Here, we declare a greeting which is populated when the websocket receives a message. We also register a button action to send a message to the server, so we can demonstrate bi-directional messaging. If you’re familiar with Play 1.x, you’ll notice that the templating is a little different.
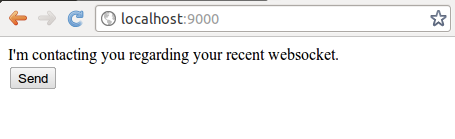
Now, when we start the app, we see the following.
Clicking the Send button generates the following log line:
1
[info] application - I'm sending a message now.
Conclusion
So, that’s all that needs to be done to create a websocket-enabled application in Play. We’ve both sent messages from, and to, the browser with simple code on both client and server side. In a real application, we would probably pass the in and out streams to a model, but it should be straightforward to see how this is done from the example.
For further information, you can look at the examples, particularly the websocket chat app, upon which this guide is based. In a future post I’d like to go into more detail by looking at the Akka actor model implementation, which is used in the chat application sample.
This article comes with a small disclaimer – Play is still a new framework to me, so some of the above code may not demonstrate best practice (although I did attempt to follow the sample application closely). If you notice anything that could be improved, let me know and I’ll update accordingly.